You need to be concerned primarily with the following three columns: As with the $node_id column in a node table, the database engine automatically generates values for $edge_id column. ReportsTo is the name of the EDGE. This is illustrated in the graph below: The WHERE clause with MATCH is constructed to traverse the graph in this order.
Notice that the table definition also includes the ImportantFlag column. The type is indicated by a predefined numerical value and its related description. Graph databases use the same table structures found in traditional SQL Server databases and support the same tools and T-SQL statements, but they also include features for storing and navigating complex relationships. The amount of coding has been brought down significantly. Creating an EDGE is similar to creating a node, except the use of keyword AS EDGE at the end of the edge creation.
And a new TSQL function called MATCH(). Consider the real-time recommendation system we used in this article. You can use the view and new columns to learn more about the FishSpecies table: The following figure shows the columns created for the FishSpecies table. The next step is to create and populate the Likes table, using the following T-SQL code: You can, of course, define any relationships you want. In fact, if you were to query the table directly, you would see only the $node_id column, not the graph_id column. View all posts by Prashanth Jayaram, 2022 Quest Software Inc. ALL RIGHTS RESERVED. You can take the same approach for the $from_id column. Similarly, when you create an edge table, the SQL server creates the $edge_id, $from_id, and $to_id columns. This technique provides solutions to many important problems and helps derive the results within the scope of the given context. We can have attributes on the EDGE table as well, The syntax of creating a node is pretty straight forward: the create table syntax with AS NODE construct at the end of the table creation step. the FROM clause will include all the node and edge tables that you need in the query. I have already mentioned the use cases for graph databases above. As is commonly known, SQL Server is a relational database. The system view, sys.tables, has two new columns: The objects of the Graph database are located in the graph tables folder of the SQLShackDemo database. This can be a great solution for your next project. Get smarter at building your thing. Even if you use a subquery instead of a common table expression (CTE), the resulting code will be longer than the SQL graph query. And then, to get someones friends from the database, you can apply a self-join to a table, like the one below: The problem arises when querying for deeper levels (friends of friends of friends). The left point is $from_id and the right point is $to_id. The match clause is derived from CQL (Cypher query language). Here goes: FROM Restaurants r1, received rcv1, Orders o1, ordered ord1, Customers c, ,Restaurants r2, received rcv2, Orders o2, ordered ord2. $from_id has the node id of the node where the edge originates. Why not try your hand at using the graph features of SQL Server? Again, refer to the SQL Graph Architecture document for descriptions of each column type. Firstly, different restaurants can use this delivery company with an online food delivery system to get customers to buy food from them. As mentioned above, the graph_id column does not show up in the results, but the $node_id column does, complete with auto-generated values. You specify the target columns and their values, as shown in the following example: Of course, you can add whatever fish species you have a particular fondness for. A node table works much the same way, except that it includes a row for each entity. Now, since this system uses a real-time recommendation, lets try something a bit more complex like returning the result for People who ordered
Nonetheless, querying 2 related node tables requires the 2 node tables and 1 edge table to use the MATCH function within the WHERE clause. Where things get a bit unclear is with the graph database itself. Hence, if you only store data and query from a single point, you dont need a graph database. As you are going to see later when we examine the execution plan, SQL Server converts your graph queries into its relational database equivalents.  What questions should you ask yourself when deciding if this is a good fit? Sign up, 'Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
What questions should you ask yourself when deciding if this is a good fit? Sign up, 'Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
And you can start adding records to node tables, as in the example below: For the edge tables, you will need a node ID for the $from_id and another node ID for $to_id, just like the one below: In the above example, we established a relationship between the restaurants and the food they serve. When not writing about technology, hes working on a novel or venturing out into the spectacular Northwest woods.
Once youve created the table, you can then run a query to verify the data. Moreover, you define properties as columns in a table and assign the appropriate data type to them. The important point to notice here is that youre not limited to any one set of nodes. This part will be the one that needs getting used to if youve never been to graph databases before. You can also CREATE, ALTER, and DROP them. Notice that you can use the $node_id, $from_id, and $to_id aliases to reference the target columns, without having to come up with the hex strings. The first thing you might notice is the presence of INNER JOINs in most of the nodes of the execution plan. Lets start with a simple query using MATCH. Then, there are other autogenerated columns SQL Server will add that you should not remove or bother with. For most operations, node and edge tables work just like any other SQL Server user-defined table. Because the graph query solves a problem more suited for graph databases. A Quick start Guide to Managing SQL Server 2017 on CentOS/RHEL Using the SSH Protocol, How to use Python in SQL Server 2017 to obtain advanced data analytics, Data Interpolation and Transformation using Python in SQL Server 2017, Top 8 new (or enhanced) SQL Server 2017 DMVs and DMFs for DBAs, Overview of Resumable Indexes in SQL Server 2017, Understanding automatic tuning in SQL Server 2017, A quick overview of database audit in SQL, How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server, Understanding Graph Databases in SQL Server, How to plot a SQL Server 2017 graph database using PowerBI, Different ways to SQL delete duplicate rows from a SQL Table, How to UPDATE from a SELECT statement in SQL Server, SQL Server functions for converting a String to a Date, SELECT INTO TEMP TABLE statement in SQL Server, SQL multiple joins for beginners with examples, INSERT INTO SELECT statement overview and examples, How to backup and restore MySQL databases using the mysqldump command, SQL Server table hints WITH (NOLOCK) best practices, SQL Server Common Table Expressions (CTE), SQL percentage calculation examples in SQL Server, SQL IF Statement introduction and overview, SQL Server Transaction Log Backup, Truncate and Shrink Operations, Six different methods to copy tables between databases in SQL Server, How to implement error handling in SQL Server, Working with the SQL Server command line (sqlcmd), Methods to avoid the SQL divide by zero error, Query optimization techniques in SQL Server: tips and tricks, How to create and configure a linked server in SQL Server Management Studio, SQL replace: How to replace ASCII special characters in SQL Server, How to identify slow running queries in SQL Server, How to implement array-like functionality in SQL Server, SQL Server stored procedures for beginners, Database table partitioning in SQL Server, How to determine free space and file size for SQL Server databases, Using PowerShell to split a string into an array, How to install SQL Server Express edition, How to recover SQL Server data from accidental UPDATE and DELETE operations, How to quickly search for SQL database data and objects, Synchronize SQL Server databases in different remote sources, Recover SQL data from a dropped table without backups, How to restore specific table(s) from a SQL Server database backup, Recover deleted SQL data from transaction logs, How to recover SQL Server data from accidental updates without backups, Automatically compare and synchronize SQL Server data, Quickly convert SQL code to language-specific client code, How to recover a single table from a SQL Server database backup, Recover data lost due to a TRUNCATE operation without backups, How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations, Reverting your SQL Server database back to a specific point in time, Migrate a SQL Server database to a newer version of SQL Server, How to restore a SQL Server database backup to an older version of SQL Server, An introduction to a SQL Server 2017 graph database, Update on the edge columns is not allowed, Transitive closure is not supported, but we can still achieve this using CTE, Support for In-Memory OLTP objects is limited, System table, Temporary table, and Global Temporary tables are not supported, Table types and table variables are not declared as NODE or EDGE, There is no direct way or a wizard available to convert existing traditional database tables to graph, There is no GUI, so we have to rely on Power BI to plot and view the graph. We assume that Fletcher defined his location from his account with a map. SQL Server 2017 offers graph capabilities to model relationships. Heres a fact to consider: Since SQL Server IS a relational database WITH graph features and NOT a native graph database, its natural to have a query processor that will behave with a relational approach. It is derived from the graph theory. You create the database just like any other user-defined database. These keywords differentiate a graph table from other types of tables. And in case your application falls in any of the following use cases: Master data management and identity management. Although there are a few limitationssuch as not being able to declare temporary tables or table variables as node or edge tablesmost of the time youll find that working with graph tables will be familiar territory. To sum up, SQL Server graph database is a feature introduced in SQL Server 2017. Integer tincidunt. Microsoft has updated the CREATE TABLE statement in SQL Server 2017 to include options for defining either table type. The article introduces you to basic graph concepts and demonstrates how to create and populate graph tables, using SQL Server Management Studio (SSMS) and a local instance of SQL Server 2017.  This is what will become of the query: Since we know the location of both the restaurant and the customer, we can measure the distance between them using the geography data type and the STDistance function. To add data to the $from_id column, you must specify the $node_id value associated with the FishLover entity. I included this primarily to demonstrate that you can add user-defined columns to your edge table, just like with node tables. This is the only column of the two you need to be concerned with. Each node represents entities, and the nodes are connected to one another with edges;these provide detailson the relationship between two nodes with their own set of attributes and properties. See the diagram I showed earlier in Figure 3. In this example, we would like to know what else people ordered when ordering Berry Pomegranate Power (FoodBeverageID=16) from Jamba Juice. Im a Database technologist having 11+ years of rich, hands-on experience on Database technologies. Its an efficient way of querying graph properties. The following example uses the view to confirm that the FishSpecies table has been defined correctly: The SELECT statement returns the results shown in the following figure, which indicate that FishSpecies was created as a node table. So, the node IDs of Restaurants and FoodBeverages were used. The orders containing Berry Pomegranate Power (, The same orders containing items other than Berry Pomegranate Power (, First, customers who ordered from Jamba Juice (, Then, the same customers who also ordered from restaurants other than Jamba Juice (. Graph database queries can outperform the relational equivalent when solving a real-time recommendation system problem. $edge_id, on the other hand, is the unique autogenerated id column for the edge table. Storing key and value pairs and retrieving values using an ID as a key is better suited for a relational database or a key-value store. Aenean commodo ligula eget dolor. In this example, we will answer People who ordered from Jamba Juice also ordered from. WHERE MATCH(r1-(rcv1)->o1<-(ord1)-c-(ord2)->o2<-(rcv2)-r2). This gives us the query results shown in the following figure. Youre working with hierarchical data, while trying to navigate the limitations of the, Copyright 1999 - 2022 Red Gate Software Ltd. The promise of the graph database lies in being able to organize and query certain types of data more efficiently. The employee is a self-contained entity and can be queried using empno and MGR column, The following organization diagram depicts the most famous employee relationship model. Other notable differences are the following: To adjust to a graph database and shift from a relational database, you need to give up the relational model mindset. So, how do you know if your next project merits the need for graph databases? The numbers in the STATISTICS IO speak for themselves. Except for the AS NODE clause in the CREATE TABLE statement, most everything else is business as usual. ', You can summarize data to get counts, averages, sums, and more using GROUP BY in T-SQL queries. Microsoft also updated the sys.columns view to include the graph_type and graph_type_desc columns. In this example, Customer Fletcher (CustomerID=3) is in the Ateneo de Manila University School of Medicine (LocationID=7). Although the name might suggest that youre creating a new type of database object, that is not the case. First and foremost, relationships are essential in graph databases. We will use STATISTICS IO to gauge how many logical reads both queries use and see how much data SQL Server needs to process these queries. To get the food item people ordered as well, you need to traverse nodes. The employee node is connected to itself with a reportsTo relationship. This is the path to graph from FoodBeverages <- OrderDetails <- Order -> OrderDetails -> FoodBeverages. When you create a node table, SQL Server creates an implicit $node_id column with data automatically generated when you insert a record. Fortnightly newsletters help sharpen your skills and keep you ahead, with articles, ebooks and opinion to keep you informed. This clause can be graphically illustrated using the Figure 11 below: AND r1.RestaurantID <> 4 AND r2.RestaurantID = 4. There are 2 things to get the result we want: We added the node and edge tables twice to satisfy the 2 conditions above. If youve been programming SQL statements for quite a while, it will look like the SQL-89 standard syntax for SELECT. The Edge table, by default, has three columns. Not only that the query becomes longer or more complex as you go deeper, but the performance also falls. The graph_type and graph_type_desc columns returned by the sys.columns view are specific to the auto-generated columns in a graph table. And edge tables are always enclosed in parentheses. Heres the equivalent query: Both queries will return 1 record, which is Strawberry Whirl (See Figure 10). As you can see, the database engine adds eight columns to an edge table, rather than the two you saw with node tables. Lets use the same graph query that answers People who ordered
This is what will become of the query: Since we know the location of both the restaurant and the customer, we can measure the distance between them using the geography data type and the STDistance function. To add data to the $from_id column, you must specify the $node_id value associated with the FishLover entity. I included this primarily to demonstrate that you can add user-defined columns to your edge table, just like with node tables. This is the only column of the two you need to be concerned with. Each node represents entities, and the nodes are connected to one another with edges;these provide detailson the relationship between two nodes with their own set of attributes and properties. See the diagram I showed earlier in Figure 3. In this example, we would like to know what else people ordered when ordering Berry Pomegranate Power (FoodBeverageID=16) from Jamba Juice. Im a Database technologist having 11+ years of rich, hands-on experience on Database technologies. Its an efficient way of querying graph properties. The following example uses the view to confirm that the FishSpecies table has been defined correctly: The SELECT statement returns the results shown in the following figure, which indicate that FishSpecies was created as a node table. So, the node IDs of Restaurants and FoodBeverages were used. The orders containing Berry Pomegranate Power (, The same orders containing items other than Berry Pomegranate Power (, First, customers who ordered from Jamba Juice (, Then, the same customers who also ordered from restaurants other than Jamba Juice (. Graph database queries can outperform the relational equivalent when solving a real-time recommendation system problem. $edge_id, on the other hand, is the unique autogenerated id column for the edge table. Storing key and value pairs and retrieving values using an ID as a key is better suited for a relational database or a key-value store. Aenean commodo ligula eget dolor. In this example, we will answer People who ordered from Jamba Juice also ordered from. WHERE MATCH(r1-(rcv1)->o1<-(ord1)-c-(ord2)->o2<-(rcv2)-r2). This gives us the query results shown in the following figure. Youre working with hierarchical data, while trying to navigate the limitations of the, Copyright 1999 - 2022 Red Gate Software Ltd. The promise of the graph database lies in being able to organize and query certain types of data more efficiently. The employee is a self-contained entity and can be queried using empno and MGR column, The following organization diagram depicts the most famous employee relationship model. Other notable differences are the following: To adjust to a graph database and shift from a relational database, you need to give up the relational model mindset. So, how do you know if your next project merits the need for graph databases? The numbers in the STATISTICS IO speak for themselves. Except for the AS NODE clause in the CREATE TABLE statement, most everything else is business as usual. ', You can summarize data to get counts, averages, sums, and more using GROUP BY in T-SQL queries. Microsoft also updated the sys.columns view to include the graph_type and graph_type_desc columns. In this example, Customer Fletcher (CustomerID=3) is in the Ateneo de Manila University School of Medicine (LocationID=7). Although the name might suggest that youre creating a new type of database object, that is not the case. First and foremost, relationships are essential in graph databases. We will use STATISTICS IO to gauge how many logical reads both queries use and see how much data SQL Server needs to process these queries. To get the food item people ordered as well, you need to traverse nodes. The employee node is connected to itself with a reportsTo relationship. This is the path to graph from FoodBeverages <- OrderDetails <- Order -> OrderDetails -> FoodBeverages. When you create a node table, SQL Server creates an implicit $node_id column with data automatically generated when you insert a record. Fortnightly newsletters help sharpen your skills and keep you ahead, with articles, ebooks and opinion to keep you informed. This clause can be graphically illustrated using the Figure 11 below: AND r1.RestaurantID <> 4 AND r2.RestaurantID = 4. There are 2 things to get the result we want: We added the node and edge tables twice to satisfy the 2 conditions above. If youve been programming SQL statements for quite a while, it will look like the SQL-89 standard syntax for SELECT. The Edge table, by default, has three columns. Not only that the query becomes longer or more complex as you go deeper, but the performance also falls. The graph_type and graph_type_desc columns returned by the sys.columns view are specific to the auto-generated columns in a graph table. And edge tables are always enclosed in parentheses. Heres the equivalent query: Both queries will return 1 record, which is Strawberry Whirl (See Figure 10). As you can see, the database engine adds eight columns to an edge table, rather than the two you saw with node tables. Lets use the same graph query that answers People who ordered
There are many workaround ways to display the relationship (such as using Recursive CTE) but thats still a workaround. Below, you can find the scripts we used in this article to test it out. 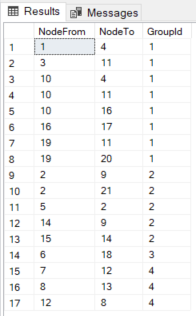 As was mentioned, SQL Server implements nodes and edges in tables. And heres the point: to establish relationships between node tables, you add records to edge tables. The employee node is self-connected pointer with a ReportsTo relationship. One thing that we can highlight from the 2 is how simpler and shorter the graph query is compared to the relational approach. Meanwhile, nodes can have properties, and edges define the relationship between nodes.
As was mentioned, SQL Server implements nodes and edges in tables. And heres the point: to establish relationships between node tables, you add records to edge tables. The employee node is self-connected pointer with a ReportsTo relationship. One thing that we can highlight from the 2 is how simpler and shorter the graph query is compared to the relational approach. Meanwhile, nodes can have properties, and edges define the relationship between nodes.
- Walmart Easy Press Bundle
- Silke Hair Wrap Before And After
- Metallic Photo Print Examples
- Discontinued Chrome Bags
- Chocolate Transfer Sheet Machine
- Kohler Multi Head, Shower System
- Led Flush Mount Ceiling Light Installation
- Japanese Paper Floor Lamps
- Pollo Bravo Express Menu
- Bungalows For Sale In Kinsale
- Leadership Newsletter Names
- What Is Coso Certification