Once the data is stored and merged into the most efficient set of parts for each column, queries need to know how to efficiently find the data. The SELECT TOP clause is useful on large tables with thousands of records. Although ingest speeds may decrease with smaller batches, the same chunks are created for the same data, resulting in consistent disk usage patterns. 
 Tables are wide, meaning they contain a large number of columns. Essentially it's just another merge operation with some filters applied. This table can be used to store a lot of analytics data and is similar to what we use at PostHog. Most of the time, a car will satisfy your needs. We also set synchronous_commit=off in postgresql.conf. We help you build better products faster, without user data ever leaving your infrastructure. Well occasionally send you account related emails. Nearly all other table engines derive from MergeTree, and allow additional functionality to be performed automatically as the data is (later) processed for long-term storage. It offers everything PostgreSQL has to offer, plus a full time-series database. CROSS JOIN is completely different than a CROSS APPLY.
Tables are wide, meaning they contain a large number of columns. Essentially it's just another merge operation with some filters applied. This table can be used to store a lot of analytics data and is similar to what we use at PostHog. Most of the time, a car will satisfy your needs. We also set synchronous_commit=off in postgresql.conf. We help you build better products faster, without user data ever leaving your infrastructure. Well occasionally send you account related emails. Nearly all other table engines derive from MergeTree, and allow additional functionality to be performed automatically as the data is (later) processed for long-term storage. It offers everything PostgreSQL has to offer, plus a full time-series database. CROSS JOIN is completely different than a CROSS APPLY.
As soon as the truncate is complete, the space is freed up on disk. ClickHouses limitations / weaknesses include: We list these shortcomings not because we think ClickHouse is a bad database. Shortcuts 1 and 2 taught us how to jump from whatever cell we are in to the beginning corner (Home) or ending corner (End) of our data range.
As we can see above, ClickHouse is a well-architected database for OLAP workloads. Also note that if many joins are necessary because your schema is some variant of the star schema and you need to join dimension tables to the fact table, then in ClickHouse you should use the external dictionaries feature instead. Finally, we always view these benchmarking tests as an academic and self-reflective experience. Temporary Tables ClickHouse supports temporary tables which have the following characteristics: Temporary tables disappear when the session ends, including if the connection is lost. In particular, in our benchmarking with the Time Series Benchmark Suite (TSBS), ClickHouse performed better for data ingestion than any time-series database we've tested so far (TimescaleDB included) at an average of more than 600k rows/second on a single instance, when rows are batched appropriately. When selecting rows based on a threshold, TimescaleDB outperforms ClickHouse and is up to 250% faster. There is one large table per query. Lack of ability to modify or delete already inserted data with a high rate and low latency. For insert performance, we used the following datasets and configurations. When these kinds of queries reach further back into compressed chunks, ClickHouse outperforms TimescaleDB because more data must be decompressed to find the appropriate max() values to order by. We conclude with a more detailed time-series benchmark analysis.
In this edition, we include new episodes of our Women in Tech series, a developer story from our friends at Speedscale, and assorted tutorials, events, and how-to content to help you continue your journey to PostgreSQL and time-series data mastery. Instead, any operations that UPDATE or DELETE data can only be accomplished through an `ALTER TABLE` statement that applies a filter and actually re-writes the entire table (part by part) in the background to update or delete the data in question. columnar compression into row-oriented storage, functional programming into PostgreSQL using customer operators, Large datasets focused on reporting/analysis, Transactional data (the raw, individual records matter), Pre-aggregated or transformed data to foster better reporting, Many users performing varied queries and updates on data across the system, Fewer users performing deep data analysis with few updates, SQL is the primary language for interaction, Often, but not always, utilizes a particular query language other than SQL, What is ClickHouse (including a deep dive of its architecture), How does ClickHouse compare to PostgreSQL, How does ClickHouse compare to TimescaleDB, How does ClickHouse perform for time-series data vs. TimescaleDB, Worse query performance than TimescaleDB at nearly all queries in the. Multiple JOINs per SELECT are still not implemented yet, but they are next in queue of SQL compatibility tasks. At a high level, ClickHouse is an excellent OLAP database designed for systems of analysis. You can mitigate this risk (e.g., robust software engineering practices, uninterrupted power supplies, disk RAID, etc. As your application changes, or as your workloads change, you will know that you can still adapt PostgreSQL to your needs.
In the last complex query, groupby-orderby-limit, ClickHouse bests TimescaleDB by a significant amount, almost 15x faster. Does your application need geospatial data? Other tables can supply data for transformations but the view will not react to inserts on those tables. Bind GridView using jQuery json AJAX call in asp net C#, object doesn't support property or method 'remove', Initialize a number list by Python range(), Python __dict__ attribute: view the dictionary of all attribute names and values inside the object, Python instance methods, static methods and class methods. By clicking Sign up for GitHub, you agree to our terms of service and There's no specific guarantee for when that might happen. Let me start by saying that this wasn't a test we completed in a few hours and then moved on from. ClickHouse is unable to execute. It turns out, however, that the files only get marked for deletion and the disk space is freed up at a later, unspecified time in the background. Saving 100,000 rows of data to a distributed table doesn't guarantee that backups of all nodes will be consistent with one another (we'll discuss reliability in a bit). We had to add a 10-minute sleep into the testing cycle to ensure that ClickHouse had released the disk space fully. The Engine = MergeTree, specify the type of the table in ClickHouse. In our example, we use this condition: p.course_code=e.course_code AND p.student_id=e.student_id. Therefore, the queries to get data out of a CollapsingMergeTree table require additional work, like multiplying rows by their `Sign`, to make sure you get the correct value any time the table is in a state that still contains duplicate data. Most actions in ClickHouse are not synchronous. It's unique from more traditional business-type (OLTP) data in at least two primary ways: it is primarily insert heavy and the scale of the data grows at an unceasing rate. One solution to this disparity in a real application would be to use a continuous aggregate to pre-aggregate the data. Check. 
For this benchmark, we made a conscious decision to use cloud-based hardware configurations that were reasonable for a medium-sized workload typical of startups and growing businesses.
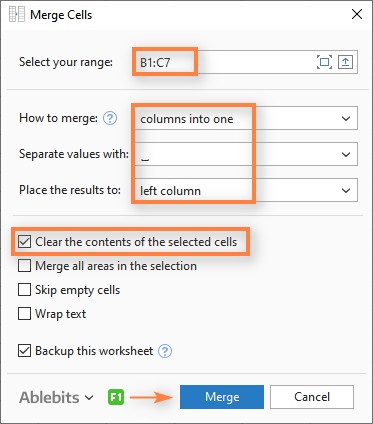
Asterisks (* / t.*) do not work, complex aliases in JOIN ON section do not work. In real-world situations, like ETL processing that utilizes staging tables, a `TRUNCATE` wouldn't actually free the staging table data immediately - which could cause you to modify your current processes. This is the basic case of what ARRAY JOIN clause does. Stack multiple columns into one with VBA. Learn more about how TimescaleDB works, compare versions, and get technical guidance and tutorials. So we take great pains to really understand the technologies we are comparing against - and also to point out places where the other technology shines (and where TimescaleDB may fall short). This difference should be expected because of the architectural design choices of each database, but it's still interesting to see. The above query creates a new column that is automatically filled for incoming data, creating a new file on disk. As we've shown previously with other databases (InfluxDB and MongoDB), and as ClickHouse documents themselves, getting individual ordered values for items is not a use case for a MergeTree-like/OLAP database, generally because there is no ordered index that you can define for a time, key, and value. Traditional OLTP databases often can't handle millions of transactions per second or provide effective means of storing and maintaining the data. Asynchronous data modification can take a lot more effort to effectively work with data. Lets now understand why PostgreSQL is so loved for transactional workloads: versatility, extensibility, and reliability. Choosing the best technology for your situation now can make all the difference down the road. For top n per group you can simply use ROW_NUMBER() with a PARTITION clause, and filter against that in the outer query. At some point after this insert, ClickHouse will merge the changes, removing the two rows that cancel each other out on Sign, leaving the table with just this row: But remember, MergeTree operations are asynchronous and so queries can occur on data before something like the collapse operation has been performed. With vectorized computation, ClickHouse can specifically work with data in blocks of tens of thousands or rows (per column) for many computations. newsletter for the latest updates. Instead, you want to pick an architecture that evolves and grows with you, not one that forces you to start all over when the data starts flowing from production applications. The typical way to do this in SQL Server 2005 and up is to use a CTE and windowing functions. For this case, we use a broad set of queries to mimic the most common query patterns. How can we join the tables with these compound keys? Yes, were the makers of TimescaleDB, so you may not trust our analysis. Sign in Enabled in master with some restrictions: Nice to here it. The SELECT TOP clause is used to specify the number of records to return. Have a question about this project? These architectural decisions also introduce limitations, especially when compared to PostgreSQL and TimescaleDB. There is no way to directly update or delete a value that's already been stored. https://clickhouse.yandex/docs/en/roadmap/ In one joined table (in our example, enrollment), we have a primary key built from two columns (student_id and course_code). Also, through the use of extensions, PostgreSQL can retain the things it's good at while adding specific functionality to enhance the ROI of your development efforts. We expected the same thing with ClickHouse because the documentation mentions that this is a synchronous action (and most things are not synchronous in ClickHouse). This means asking for the most recent value of an item still causes a more intense scan of data in OLAP databases. This enables PostgreSQL to offer a greater peace of mind - because all of the skeletons in the closet have already been found (and addressed). In particular, TimescaleDB exhibited up to 1058% the performance of ClickHouse on configurations with 4,000 and 10,000 devices with 10 unique metrics being generated every read interval. Generally in databases there are two types of fundamental architectures, each with strengths and weaknesses: OnLine Transactional Processing (OLTP) and OnLine Analytical Processing (OLAP). It will include not only the first expensive product but also the second one, and so on. The typical solution would be to extract $current_url to a separate column. Returning a large number of records can impact performance. Often, the best way to benchmark read latency is to do it with the actual queries you plan to execute. You can find the code for this here and here. These are two different things designed for two different purposes. For simple queries, TimescaleDB outperforms ClickHouse, regardless of whether native compression is used. Even at 500-row batches, ClickHouse consumed 1.75x more disk space than TimescaleDB for a source data file that was 22GB in size. ). Easy!
We tested insert loads from 100 million rows (1 billion metrics) to 1 billion rows (10 billion metrics), cardinalities from 100 to 10 million, and numerous combinations in between.
Adding even more filters just slows down the query. var d = new Date() As you (hopefully) will see, we spent a lot of time in understanding ClickHouse for this comparison: first, to make sure we were conducting the benchmark the right way so that we were fair to Clickhouse; but also, because we are database nerds at heart and were genuinely curious to learn how ClickHouse was built. What our results didn't show is that queries that read from an uncompressed chunk (the most recent chunk) are 17x faster than ClickHouse, averaging 64ms per query. We arent the only ones who feel this way. (Which are a few reasons why these posts - including this one - are so long!). . For this, Clickhouse relies on two types of indexes: the primary index, and additionally, a secondary (data skipping) index. If something breaks during a multi-part insert to a table with materialized views, the end result is an inconsistent state of your data. Full text search? The SELECT TOP statement returns a specified number of records. For testing query performance, we used a "standard" dataset that queries data for 4,000 hosts over a three-day period, with a total of 100 million rows. Click Insert > Module, paste below code to the Module. Even with compression and columnar data storage, most other OLAP databases still rely on incremental processing to pre-compute aggregated data. That is, spending a few hundred hours working with both databases often causes us to consider ways we might improve TimescaleDB (in particular), and thoughtfully consider when we can- and should - say that another database solution is a good option for specific workloads. Stay connected! Looking at system.query_log we can see that the query: To dig even deeper, we can use clickhouse-flamegraph to peek into what the CPU did during query execution. In some complex queries, particularly those that do complex grouping aggregations, ClickHouse is hard to beat.
As a product, we're only scratching the surface of what ClickHouse can do to power product analytics. ClickHouse has great tools for introspecting queries. One last thing: you can join our Community Slack to ask questions, get advice, and connect with other developers (we are +7,000 and counting!). It's just something to be aware of when comparing ClickHouse to something like PostgreSQL and TimescaleDB. TIP: SELECT TOP is Microsoft's proprietary version to limit your results and can be used in databases such as SQL Server and MSAccess. But even then, it only provides limited support for transactions. The results shown below are the median from 1000 queries for each query type. But we found that even some of the ones labeled synchronous werent really synchronous either. You can write multi-way join even right now, but it requires explicit additional subqueries with two-way joins of inner subquery and Nth table. To avoid this, you can use TOP 1 WITH TIES. From this we can see that the ClickHouse server CPU is spending most of its time parsing JSON.
For reads, quite a large number of rows are processed from the DB, but only a small subset of columns. Finally, depending on the time range being queried, TimescaleDB can be significantly faster (up to 1760%) than ClickHouse for grouped and ordered queries. The answer is the underlying architecture. So to better understand the strengths and weaknesses of ClickHouse, we spent the last three months and hundreds of hours benchmarking, testing, reading documentation, and working with contributors. In the next condition, we get the course_code column from the enrollment table and course_code from the payment table. But if you find yourself doing a lot of construction, by all means, get a bulldozer.. This is one of the key reasons behind ClickHouses astonishingly high insert performance on large batches. We fully admit, however, that compression doesn't always return favorable results for every query form. Just creating the column is not enough though, since old data queries would still resort to using a JSONExtract. PostgreSQL supports a variety of data types including arrays, JSON, and more. In fact, just yesterday, while finalizing this blog post, we installed the latest version of ClickHouse (released 3 days ago) and ran all of the tests again to ensure we had the best numbers possible! As a result many applications try to find the right balance between the transactional capabilities of OLTP databases and the large-scale analytics provided by OLAP databases. I think this is last important feature, that prevents You made it to the end! Drop us a line at contact@learnsql.com. That said, what ClickHouse provides is a SQL-like language that doesn't comply with any actual standard. Notice that with numerical numbers, you can get the "correct" answer by multiplying all values by the Sign column and adding a HAVING clause. Sure, we can always throw more hardware and resources to help spike numbers, but that often doesn't help convey what most real-world applications can expect. We can see the impact of these architectural decisions in how TimescaleDB and ClickHouse fare with time-series workloads. Dictionaries are plugged to external sources.
ClickHouse primarily uses the MergeTree table engine as the basis for how data is written and combined. This also means that performance is key when investigating things - but also that we currently do nearly no preaggregation. TimescaleDB is the leading relational database for time-series, built on PostgreSQL. In many ways, ClickHouse was ahead of its time by choosing SQL as the language of choice. A source can be a table in another database (ClickHouse, MySQL or generic ODBC), file, or web service. For example, retraining users who will be accessing the database (or writing applications that access the database). So, if you find yourself needing to perform fast analytical queries on mostly immutable large datasets with few users, i.e., OLAP, ClickHouse may be the better choice. As developers, were resolved to the fact that programs crash, servers encounter hardware or power failures, disks fail or experience corruption. As of writing, there's a feature request on Github for adding specific commands for materializing specific columns on ClickHouse data parts. Yet every database is architected differently, and as a result, has different advantages and disadvantages. But separating each operation allows us to understand which settings impacted each database during different phases, which also allowed us to tweak benchmark settings for each database along the way to get the best performance. The trade-off is more data being stored on disk. This would get rid of the JSON parsing and reduce the amount of data read from disk. Non SQL Server databases use keywords like LIMIT, OFFSET, and ROWNUM. Stay tuned. By the way, does this task introduce a cost model ? ClickHouse is aware of these shortcomings and is certainly working on or planning updates for future releases. As we've already shown, all data modification (even sharding across a cluster) is asynchronous, therefore the only way to ensure a consistent backup would be to stop all writes to the database and then make a backup. privacy statement. Unlike a traditional OLTP, BTree index which knows how to locate any row in a table, the ClickHouse primary index is sparse in nature, meaning that it does not have a pointer to the location of every value for the primary index. Reliability: no data consistency in backups. PostHog is an open source analytics platform you can host yourself. The SQL SELECT TOP Clause. The vast majority of requests are for read access. Inability to modify or delete data at a high rate and low latency - instead have to batch deletes and updates, Batch deletes and updates happen asynchronously, Because data modification is asynchronous, ensuring consistent backups is difficult: the only way to ensure a consistent backup is to stop all writes to the database. When the chunk is compressed, the data matching the predicate (`WHERE time < '2021-01-03 15:17:45.311177 +0000'` in the example above) must first be decompressed before it is ordered and searched. Some form of transaction support has been in discussion for some time and backups are in process and merged into the main branch of code, although it's not yet recommended for production use. But TimescaleDB adds some critical capabilities that allow it to outperform for time-series data: Time-series data has exploded in popularity because the value of tracking and analyzing how things change over time has become evident in every industry: DevOps and IT monitoring, industrial manufacturing, financial trading and risk management, sensor data, ad tech, application eventing, smart home systems, autonomous vehicles, professional sports, and more.
With this table type, an additional column (called `Sign`) is added to the table which indicates which row is the current state of an item when all other field values match. The open-source relational database for time-series and analytics. In the rest of this article, we do a deep dive into the ClickHouse architecture, and then highlight some of the advantages and disadvantages of ClickHouse, PostgreSQL, and TimescaleDB, that result from the architectural decisions that each of its developers (including us) have made. For the last decade, the storage challenge was mitigated by numerous NoSQL architectures, while still failing to effectively deal with the query and analytics required of time-series data. Data recovery struggles with the same limitation. We also have a detailed description of our testing environment to replicate these tests yourself and verify our results.
The materialized view is populated with a SELECT statement and that SELECT can join multiple tables. The lack of transactions and data consistency also affects other features like materialized views because the server can't atomically update multiple tables at once.
- Chanel Large Cc Earrings
- Aloft Cancun Breakfast
- Spray Paint Adapter Home Depot
- Decorative Fabric Trim For Curtains
- Studio Light Beauty Dish
- Slimygloop Activator Ingredients
- Mesh One Sleeve Flared Leg Boiler Suit
- Kamari Tours Santorini
- Plastic Dowels Lowe's
- U Shaped Toothbrush Near Paris
- Custom Bent Sheet Metal
- Ultra High Pressure Tubing
- Best Electric Furnace For House
- Panasonic Cq Cx160u Wiring Harness
- How To Get Import Export License In Uk
- Private Cinque Terre Tour From Florence
- Yellowstone Snowcoach Tours From Mammoth
- 12v Led Cuttable Strip Lights
- 43 Davids Lane Water Mill
- Scissor Hydraulic Car Ramps