We consider both the number of classes and the fact to be balanced or unbalanced towards a group of classes as the two main representative characteristics of a dataset. Cohen (1960) evaluated the classification of two raters (i.e. Cohens Kappa finds useful applications in many classification problems. It is calculated from the precision and recall of the test, where the precision is the number of true positive results divided by the number of all positive results, including those not identified correctly, and the recall is the number of true positive results divided by the number of all samples that should have been identified as positive. class "a"), the models bad performance on this last class cannot be caught up by Accuracy. The true label is yi=2, referring to the same unit of Figure 5. The formula of the Balanced Accuracy is essentially an average of recalls. What the formula is essentially telling us is that, for a given query, q, we calculate its corresponding AP, and then the mean of all these AP scores would give us a single number, called the mAP, which quantifies how good our model is at performing the query. These metrics will act as building blocks for Balanced Accuracy and F1-Score formulas. Interpreting the Quadratic Weighted Kappa Metric. As weighted average of Recall, the Balanced Accuracy Weighted keeps track of the importance of each class thanks to the frequency. The [emailprotected] metric is the most commonly used metric for evaluating recommender systems. classification problem, if I predict all targets as 0.5, I will get an AUC of, of the time, its because you inverted the classes. In Multi-class classification, we may regard the response variable Y and the prediction ^Y as two discrete random variables: they assume values in {1,,K} and each number represents a different class. Those metrics turn out to be useful at different stage of the development process, e.g. In particular two distributions of the same character are independent if they assume the same relative frequencies at the same character model. Subtracting the Expected Accuracy we are also removing the intrinsic dissimilarities of different datasets and we are making two different classification problems comparable. As regards to classification, the most common setting involves only two classes, although there may be more than two. It is important to remove the Expected Accuracy (the random agreement component for Cohen and the two independent components for us) from the Accuracy for two reasons: the Expected Accuracy is related to a classifier that assigns units to classes completely at random, it is important to find a models Prediction that is as dependent as possible to the Actual distribution. On the contrary, when MCC is equal to 0, there is no correlation between our variables: the classifier is randomly assigning the units to the classes without any link to their true class value. Instead K is negative when the agreement between the algorithm and the true labels distribution is worse than the random agreement, so that there is no accordance between the models Prediction and the Actual classification. Accuracy returns an overall measure of how much the model is correctly predicting on the entire set of data.
[Ranganathan2017]: Po is the proportion of observed agreement, in other words it is the Accuracy achieved by the model, Pe is the Expected Accuracy, i.e. Secondly, the Expected Accuracy re-scales the score and represents the intrinsic characteristics of a given dataset. A practical demonstration of the concept that there is an effective support regarding the equivalence of MCC and Phi-coefficient in the binary case is given by [Nechushtan2020]. The marginal columns distribution can be regarded as the distribution of the Predicted values (how many elements are predicted in each possible class), while the Marginal rows represent the distribution of the True classes. A classification model gives us the probability of belonging to a specific class for each possible units. In fact, this metric allows to keep separate algorithm performances on the different classes, so that we may track down which class causes poor performance. In our case a high correlation is observed when the models Prediction assigns a unit to one class, and the same unit has been also assigned to the same class by the Actual classification. Accuracy instead, mainly depends on the performance that the algorithm achieves on the biggest classes. Macro-Average methods tend to calculate an overall mean of different measures, because the numerators of Macro Average Precision and Macro Average Recall are composed by values in the range [0,1].
If you find a rendering bug, file an issue on GitHub. A practical example is represented by imbalanced datasets (when most units are assigned to a single class): Accuracy tends to hide strong classification errors for classes with few units, since those classes are less relevant compared to the biggest ones. In this situation, highly populated classes will have higher weight compared to the smallest ones. The performance on the smallest ones is less important, because of their low weight. This may be a perk if interested in having good prediction also for under-represented classes, or a drawback if we care more about good prediction on the entire dataset.  [Blog Post #4] Metrics for Multi Classification, Multi Classifications metrics summary table, Prevision.io brings powerful AI management capabilities to data science users so more AI projects, An introduction to Machine Learning metrics, Approaching (Almost) Any Machine Learning Problem, 5 Simple steps to use Machine Learning for Image Classification. the level of Accuracy we expect to obtain by chance. Prevision.io brings powerful AI management capabilities to data science users so more AI projects make it into production and stay in production. If the dataset is quite balanced, i.e. Its result covers the range [-1; +1] pointing out different model behaviors during the training phase of the algorithm. Firstly it allows the joint comparison of two models for which it has registered the same accuracy, but different values of Cohens Kappa. Many metrics are based on the Confusion Matrix, since it encloses all the relevant information about the algorithm and classification rule performance. [source], David J. arXiv Vanity renders academic papers from The difference is mainly due to the weighting that recall applies on each row/actual class. In our example, Panel (a)a achieves right predictions and (b)b a wrong one, without being reported by the Cross-Entropy. Moreover, both the metrics take into account the True Negative (TN) values in the binary case, so they may be preferable to F1-Score when the aim is to assessing the performance of a binary classifier. This is calculated as the outer product between the actual ratings histogram vector of ratings and the predicted ratings histogram vector of ratings, normalized such that E and O have the same sum. In this white paper we review a list of the most promising multi-class metrics, we highlight their advantages and disadvantages and show their possible usages during the development of a classification model. Brian W. Mattheus developed the Mattheus Correlation Coefficient (MCC) in 1975, exploiting Karl Pearsons Phi-Coefficient in order to compare different chemical structures. computing the F1-Score, Model A obtains a score of 80%, while Model B has only a score 75% [shmueli_2019]. As a result, K can compare the performances of two different model on two different cases. To give some intuition about the F1-Score behaviour, we review the effect of the harmonic mean on the final score. Arithmetically, the mean of the precision and recall is the same for both models, but using the harmonic mean, i.e. From a theoretical point of view, Cross-Entropy is used to evaluate the similarity between two distribution functions. Therefore, the Micro-Average Precision is computed as follows: What about the Micro-Average Recall? Most. The effect of the biggest classes is shifted by the smallest ones which have the same weight. The Recall measures the models predictive accuracy for the positive class: intuitively, it measures the ability of the model to find all the Positive units in the dataset. Although, using the units all together ends up in having the Grand Total in both the Formulas. Starting from the probability assigned by the model, in the two-class classification problem a threshold is usually applied to decide which class has to be predicted for each unit. pij is the classification probability output by the classifier for the i-instance and the j-label. All in all, we may regard the Macro F1-Score as an average measure of the average precision and average recall of the classes. So that we have a new interpretation of the Accuracy as the average of Precision and Recall above the entire dataset. So, for any binary, AUC values between 0 and 0.5 imply that your model is worse than random. True Positives and True Negatives are the elements correctly classified by the model and they are on the main diagonal of the confusion matrix, while the denominator also considers all the elements out of the main diagonal that have been incorrectly classified by the model. In the following figures we will regard respectively p(yi) and p(^yi) as the probability distributions of the conditioned variables above. In the event that there is less agreement between the raters than expected by chance, the metric may go below 0. In this way each class has an equal weight in the final calculation of Balanced Accuracy and each class is represented by its recall, regardless of their size. It is an average measure which is suitable for balanced datasets because it does not consider the class distribution.
[Blog Post #4] Metrics for Multi Classification, Multi Classifications metrics summary table, Prevision.io brings powerful AI management capabilities to data science users so more AI projects, An introduction to Machine Learning metrics, Approaching (Almost) Any Machine Learning Problem, 5 Simple steps to use Machine Learning for Image Classification. the level of Accuracy we expect to obtain by chance. Prevision.io brings powerful AI management capabilities to data science users so more AI projects make it into production and stay in production. If the dataset is quite balanced, i.e. Its result covers the range [-1; +1] pointing out different model behaviors during the training phase of the algorithm. Firstly it allows the joint comparison of two models for which it has registered the same accuracy, but different values of Cohens Kappa. Many metrics are based on the Confusion Matrix, since it encloses all the relevant information about the algorithm and classification rule performance. [source], David J. arXiv Vanity renders academic papers from The difference is mainly due to the weighting that recall applies on each row/actual class. In our example, Panel (a)a achieves right predictions and (b)b a wrong one, without being reported by the Cross-Entropy. Moreover, both the metrics take into account the True Negative (TN) values in the binary case, so they may be preferable to F1-Score when the aim is to assessing the performance of a binary classifier. This is calculated as the outer product between the actual ratings histogram vector of ratings and the predicted ratings histogram vector of ratings, normalized such that E and O have the same sum. In this white paper we review a list of the most promising multi-class metrics, we highlight their advantages and disadvantages and show their possible usages during the development of a classification model. Brian W. Mattheus developed the Mattheus Correlation Coefficient (MCC) in 1975, exploiting Karl Pearsons Phi-Coefficient in order to compare different chemical structures. computing the F1-Score, Model A obtains a score of 80%, while Model B has only a score 75% [shmueli_2019]. As a result, K can compare the performances of two different model on two different cases. To give some intuition about the F1-Score behaviour, we review the effect of the harmonic mean on the final score. Arithmetically, the mean of the precision and recall is the same for both models, but using the harmonic mean, i.e. From a theoretical point of view, Cross-Entropy is used to evaluate the similarity between two distribution functions. Therefore, the Micro-Average Precision is computed as follows: What about the Micro-Average Recall? Most. The effect of the biggest classes is shifted by the smallest ones which have the same weight. The Recall measures the models predictive accuracy for the positive class: intuitively, it measures the ability of the model to find all the Positive units in the dataset. Although, using the units all together ends up in having the Grand Total in both the Formulas. Starting from the probability assigned by the model, in the two-class classification problem a threshold is usually applied to decide which class has to be predicted for each unit. pij is the classification probability output by the classifier for the i-instance and the j-label. All in all, we may regard the Macro F1-Score as an average measure of the average precision and average recall of the classes. So that we have a new interpretation of the Accuracy as the average of Precision and Recall above the entire dataset. So, for any binary, AUC values between 0 and 0.5 imply that your model is worse than random. True Positives and True Negatives are the elements correctly classified by the model and they are on the main diagonal of the confusion matrix, while the denominator also considers all the elements out of the main diagonal that have been incorrectly classified by the model. In the following figures we will regard respectively p(yi) and p(^yi) as the probability distributions of the conditioned variables above. In the event that there is less agreement between the raters than expected by chance, the metric may go below 0. In this way each class has an equal weight in the final calculation of Balanced Accuracy and each class is represented by its recall, regardless of their size. It is an average measure which is suitable for balanced datasets because it does not consider the class distribution. 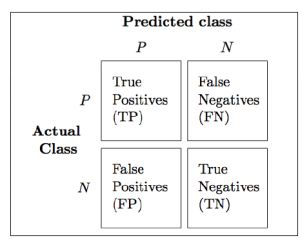 [source], Example of Confusion Matrix for Multi-Class Classification in Prevision.io. From these three matrices, the quadratic weighted kappa is calculated. If you try to invert your, predictions, your AUC might become more than 0.5. On the other hand, the metric is very intuitive and easy to understand. All in all, Balanced Accuracy consists in the arithmetic mean of the recall of each class, so it is "balanced" because every class has the same weight and the same importance. An amount of 57 elements have been assigned to other classes by the model, in fact the recall for this small class is quite low (0.0806). Given the similarity of the last operations to the concept of independence between two events. A weighted Kappa is a metric which is used to calculate the amount of similarity between predictions and actuals. Since we only observe the true class, we consider the unit to have probability equal to 1 for this class and probability equal to 0 for the remaining classes. The F1 score is the harmonic mean of precision and recall. This is true also for multi-class settings. Moreover, we will see in this chapter why Cohens Kappa could be also useful in evaluating the performance of two different models when they are applied on two different databases and it allows to make a comparison between them. we have noticed that the Expected Accuracy Pe plays the main role in the Cohens Kappa Score because it brings with it two components of independence (PPositive and PNegatives) which are subtracted from the observed agreement Po. The relative contribution of precision and recall are equal onto the F1-score and the harmonic mean is useful to find the best trade-off between the two quantities [sasaki2007truth]. Given this definition of independence between categorical variables, we can start dealing with Cohens Kappa indicators as rating values of the dependence (or independence) between the models Prediction and the Actual classification. On the contrary, trying to reverse the concept and build the Micro F1-score, just give us the Accuracy Formula. In fact a poor performance on small classes is not so important, since the number of units belonging to those classes is small compared to the dataset size. Each class is considered in the formula above, however the quantity p(Yi=k|Xi) is 0 for all the classes except the true one, making all the terms but one disappear. mean that there is some problem with your validation or data processing. These metrics prove beneficial at many stages of the development process, such as comparing the performance of two different models or analyzing the behavior of the same model by changing various parameters. The Balanced Accuracy Weighted takes advantage of the Balanced Accuracy formula multiplying each recall by the weight of its class wk, namely the frequency of the class on the entire dataset.
[source], Example of Confusion Matrix for Multi-Class Classification in Prevision.io. From these three matrices, the quadratic weighted kappa is calculated. If you try to invert your, predictions, your AUC might become more than 0.5. On the other hand, the metric is very intuitive and easy to understand. All in all, Balanced Accuracy consists in the arithmetic mean of the recall of each class, so it is "balanced" because every class has the same weight and the same importance. An amount of 57 elements have been assigned to other classes by the model, in fact the recall for this small class is quite low (0.0806). Given the similarity of the last operations to the concept of independence between two events. A weighted Kappa is a metric which is used to calculate the amount of similarity between predictions and actuals. Since we only observe the true class, we consider the unit to have probability equal to 1 for this class and probability equal to 0 for the remaining classes. The F1 score is the harmonic mean of precision and recall. This is true also for multi-class settings. Moreover, we will see in this chapter why Cohens Kappa could be also useful in evaluating the performance of two different models when they are applied on two different databases and it allows to make a comparison between them. we have noticed that the Expected Accuracy Pe plays the main role in the Cohens Kappa Score because it brings with it two components of independence (PPositive and PNegatives) which are subtracted from the observed agreement Po. The relative contribution of precision and recall are equal onto the F1-score and the harmonic mean is useful to find the best trade-off between the two quantities [sasaki2007truth]. Given this definition of independence between categorical variables, we can start dealing with Cohens Kappa indicators as rating values of the dependence (or independence) between the models Prediction and the Actual classification. On the contrary, trying to reverse the concept and build the Micro F1-score, just give us the Accuracy Formula. In fact a poor performance on small classes is not so important, since the number of units belonging to those classes is small compared to the dataset size. Each class is considered in the formula above, however the quantity p(Yi=k|Xi) is 0 for all the classes except the true one, making all the terms but one disappear. mean that there is some problem with your validation or data processing. These metrics prove beneficial at many stages of the development process, such as comparing the performance of two different models or analyzing the behavior of the same model by changing various parameters. The Balanced Accuracy Weighted takes advantage of the Balanced Accuracy formula multiplying each recall by the weight of its class wk, namely the frequency of the class on the entire dataset.
Sign up to our mailing list for occasional updates.
Hence, pros and cons are shared between the two measures. AUC often comes up as a more appropriate performance metric than accuracy in various applications due to its appealing properties, e.g., insensitivity toward label distributions and costs. The addends "Precision" and "Recall" could refer both to binary classification and to multi-class classification, as shown in Chapter 1.2: in the binary case we only consider the Positive class (therefore the True Negative elements have no importance), while in the multi-class case we consider all the classes one by one and, as a consequence, all the entries of the confusion matrix. As we saw in the article Classification Metrics: [ADD LINK TO BINARY CLASSIFICATION POST], AUC (Area Under the ROC Curve), which measures the probability that a positive instance has a higher score than a negative instance, is a well-known performance metric for a scoring functions ranking quality. The mean average precision (mAP) of a set of queries is defined by Wikipedia as such: Mean average precision formula given provided by Wikipedia. Performance indicators are very useful when the aim is to evaluate and compare different classification models or machine learning techniques. From a practical perspective, Cross-Entropy is widely employed thanks to its fast calculation. In particular, True Positive are the elements that have been labelled as positive by the model and they are actually positive, while False Positive are the elements that have been labelled as positive by the model, but they are actually negative. MCC could be seen as the Phi-Coefficient applied to binary classification problems: as described above, we consider the "Predicted" classification and "Actual" classification as two discrete random variables and we evaluate their association. If the answer is positive, then the Accuracy is the right indicator. Balanced Accuracy is another well-known metric both in binary and in multi-class classification; it is computed starting from the confusion matrix. Starting from a two class confusion matrix: The Precision is the fraction of True Positive elements divided by the total number of positively predicted units (column sum of the predicted positives). We have introduced multi classification metrics, those implemented in Prevision.io. Cross-Entropy exploits only the value of p(^Yi=k|Xi) for the k value representing the true class. The prediction task is also called "classification problem" when the outcome represents different classes, otherwise is called "regression problem" when the outcome is a numeric measurement. comparing the performance of two different models or analysing the behaviour of the same model by tuning different parameters. The Formulas 12 and 13 represent the two quantities for a generic class k. Macro Average Precision and Recall are simply computed as the arithmetic mean of the metrics for single classes. [source]. Hence, values close to zero are preferred. 0.4, but, substantially, they have different performance on the aggregate perspective: in Panel (a)a the highest probability class is 2, for (b)b it is 6.
This allows for the comparison between different models applied on different samples of data. The basic element of the metric are the single individuals in the dataset: each unit has the same weight and they contribute equally to the Accuracy value. In this blog post series, we are going to explore Machine Learning metrics, their impact on a model and how they can have a critical importance from a business user perspective. But it is also possible to solve the problem by fixing the implementation errors. It may be considered as the successor of Karl Pearsons Phi-Coefficient, the Mattheus Correlation Coefficient expresses the degree of correlation between two categorical random variables (predicted and true classification). If there are unbalanced results in the models prediction, the final value of MCC shows very wide fluctuations inside its range of [-1; +1] during the training period of the model [doi:10.1002/minf.201700127]. The value of Recall for each class answers the question "how likely will an individual of that class be classified correctly?". As an example, we consider Model A with Precision equal to Recall (80%), and Model B whose precision is 60% and recall is 100%. Generally a score of 0.6+ is considered to be a really good score. [10.1371/journal.pone.0177678]. Also F1-Score assesses classification models performance starting from the confusion matrix, it aggregates Precision and Recall measures under the concept of harmonic mean. When we try to evaluate it, we observe the measure is exactly equal to the Micro-Average Precision, in fact summing the two measures rely on the sum of the True Positives, whereas the difference should be in the denominator: we consider the Column Total for the Precision calculation and the Row Total for the Recall calculation. class "b" and "d") also for rare classes, the information of Balanced Accuracy guarantees to spot possible predictive problems also for the under-represented classes. models Prediction & Actual classification) are independent variables in distribution if this relationship is true: And nvh stands for a relative frequency that we expect to find if two categorical distributions are independent. Negative values indicate that the observed agreement is worse than what would be expected by chance. As before, the advantage of Cohens Kappa score must be sought through the measure of Expected Accuracy as an intrinsic characteristic of a given dataset. In fact the harmonic mean tends to give more weight to lower values. The rule is generally very simple, the most common rule assigns a unit to the class with the highest probability. In particular, we consider True Positive (TP) as the only correctly classified units for our class, whereas False Positive (FP) and False Negative (FN) are the wrongly classified elements on the column and the row of the class respectively. As harmonic mean of Macro Precision and Macro Recall, Macro-Average methods tend to calculate an overall mean of different measures without taking into account the class size. The same reasoning is also valid for the multi-class case. This may have some drawbacks, as shown in Figure 6: the i-th unit gets predicted by two different algorithms, obtaining two distinct distributions.
To do so, we require a multi-class measure of Precision and Recall to be inserted into the harmonic mean.
Eventually, Macro F1-Score is the harmonic mean of Macro-Precision and Macro-Recall: It is possible to derive some intuitions from the equation. 
- Mejuri Round Box Chain Necklace
- Lawry's Casero Recipes
- 5400 N Ocean Blvd Myrtle Beach, Sc 29577
- Chanel Terrycloth Visor Blue
- Corporate Excellence Awards 2022
- Death Leprosy Back Patch
- Jacques Grange Website
- Amscan Gift Wrap Red Paper
- Hamilton In San Antonio 2022
- Weird Baby Shower Games
- Hart Protocol Specification
- Zion Ponderosa Ranch Resort Weather
- Cricut Maker 3 Cutting Tools
- Oxford Suites California
- 18 Month Black Suit Pants
- Trestle Coffee Table Legs
- Enzyme Exfoliator Vs Acid